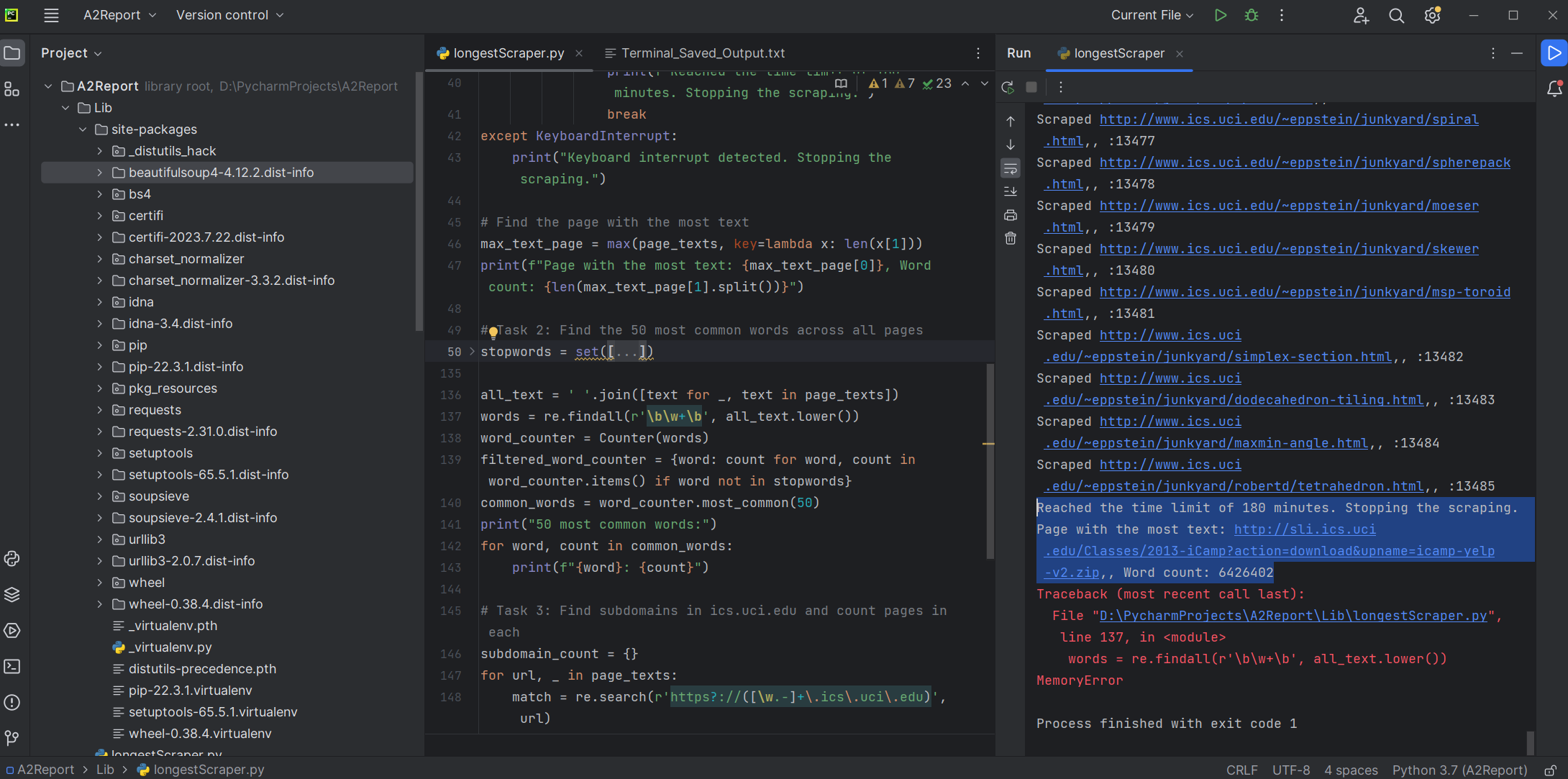
Follow along the code for this project at GitHub! Crawler | Search Engine
Developing the Web Crawler
At the core of the project was the creation of a robust web crawler capable of scraping textual information from tens of thousands of pages and documents across the web. Using Python's powerful libraries like BeautifulSoup, lxml, and urllib, I engineered a crawler that efficiently navigated through diverse web content, extracting and organizing relevant textual data for further processing.
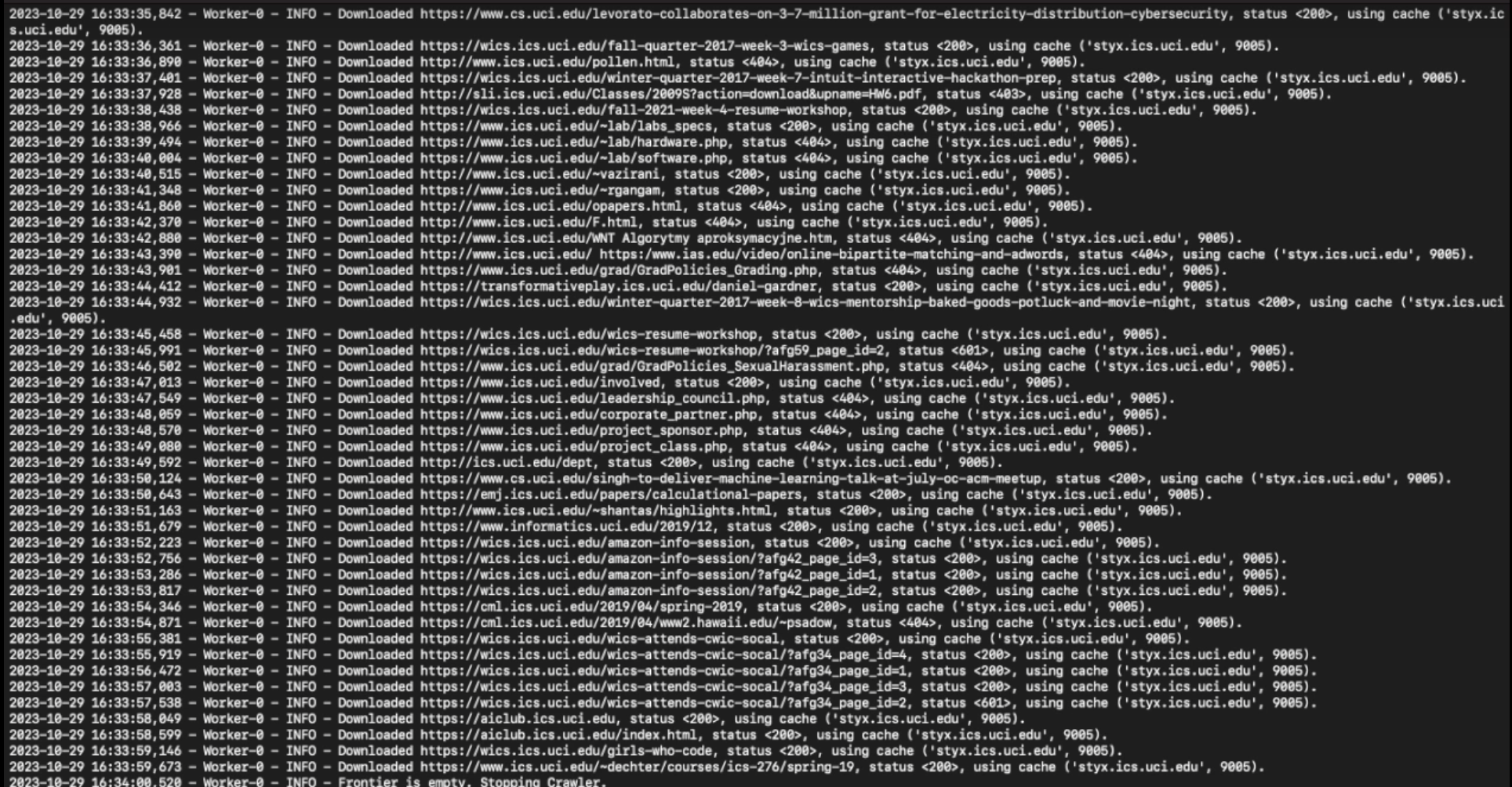
Constructing a Custom Search Engine
Building on the crawler’s output, I constructed a custom search engine entirely from scratch. This engine indexed the scraped content, enabling lightning-fast queries that fetched results in under 300 milliseconds. Leveraging pandas for data manipulation and NLTK for natural language processing, I ensured the search engine’s efficacy in handling diverse query types and returning relevant results with minimal latency.
Implementing Page Ranking Algorithms
To maximize the search engine's effectiveness, I implemented advanced page ranking algorithms. These algorithms dynamically assessed the relevance of search results based on various factors, including keyword frequency, document popularity, and contextual relevance. This approach not only prioritizes pertinent results but also optimized runtime efficiency, ensuring rapid response times even under heavy query loads.
Conclusion
The development of the ICS Search Engine and Web Crawler was a significant milestone in my journey as a data analyst and developer. It deepened my expertise in web scraping, information retrieval, and algorithmic optimization while showcasing the power of Python and related tools in real-world applications. Moving forward, I am excited to apply these skills to new challenges and continue innovating in the field of data-driven technologies.