An Investigation of Classification Methods for the IMDB Dataset
Dataset: IMDb Movie Reviews
Classification Methods: kNN, Logistic Regression, Neural Networks, Random Forests
Date: 10 June 2024
Collaborators: n/a
Summary
This project aims to explore machine learning methods and their development processes by training on an IMDb ratings dataset to predict whether a user had a positive or negative sentiment towards a given movie. In this project we utilized kNN, Logistic Regression, Feedforward Neural Network, and Random Forest models to identify the most accurate fit. Ultimately, the Logistic Regression and Random Forest models performed the best, the latter being slightly less generalizable to new data.
Data Description
The dataset we used, ‘IMDb Movie Reviews’, is a sentiment analysis dataset containing over 50,000 binary (positive or negative) responses in the form of reviews from the Internet Movie Database. The dataset only contains polarizing reviews, meaning neutral ratings were not included. Other measures were taken to ensure the data wasn’t too heavily biased, such as limiting the number of reviews allowed for a single movie to 30. The source website also links to a Stanford publication that uses this dataset, entitled “Learning Word Vectors for Sentiment Analysis”, which expands to an even larger dataset to serve as a robust benchmark.
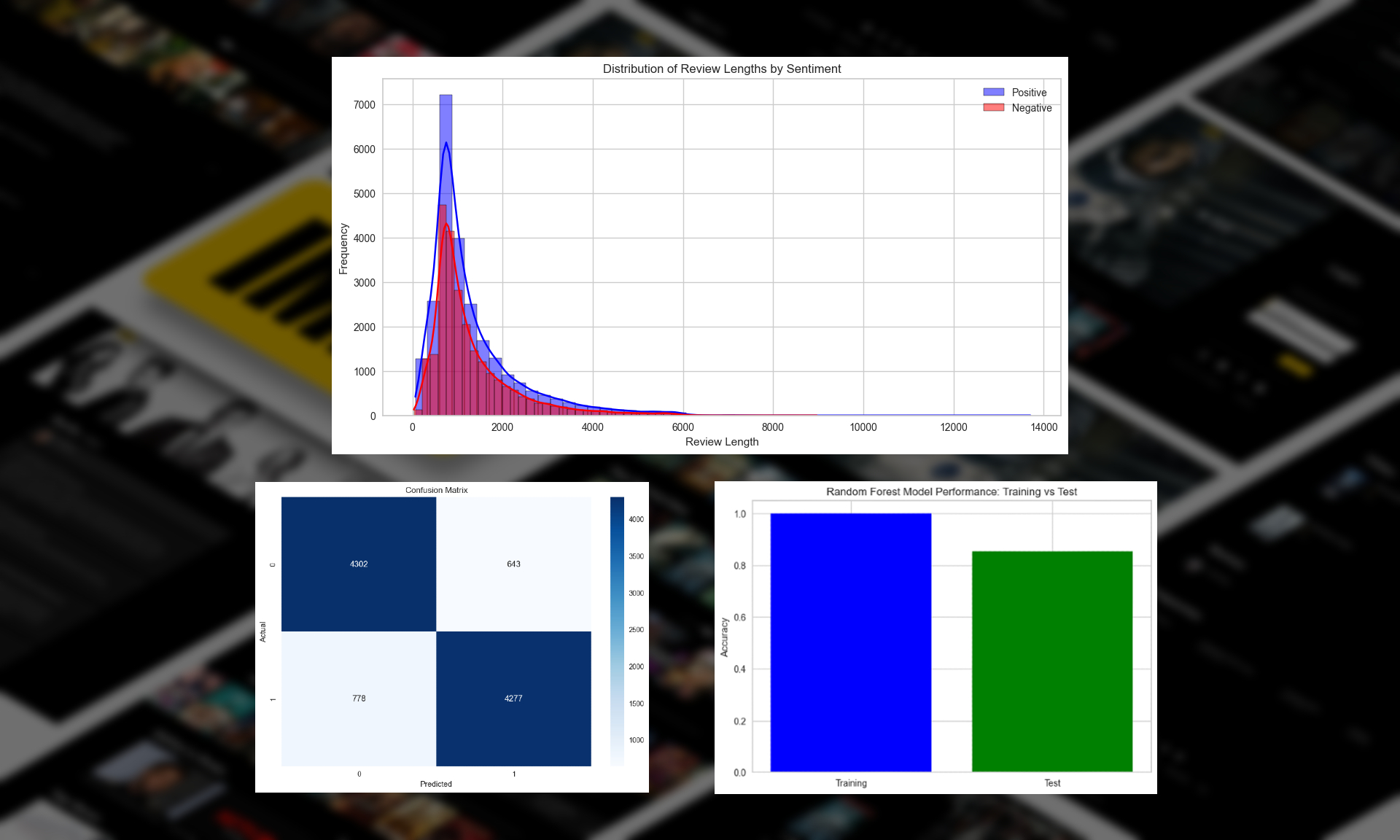
In terms of exploratory analysis, distribution of sentiments did not need to be visualized, as the dataset already evenly split the responses to be half positive and half negative. The first relationship we visualized was between the distribution of review length and sentiment. (Distribution plot in Appendix A).
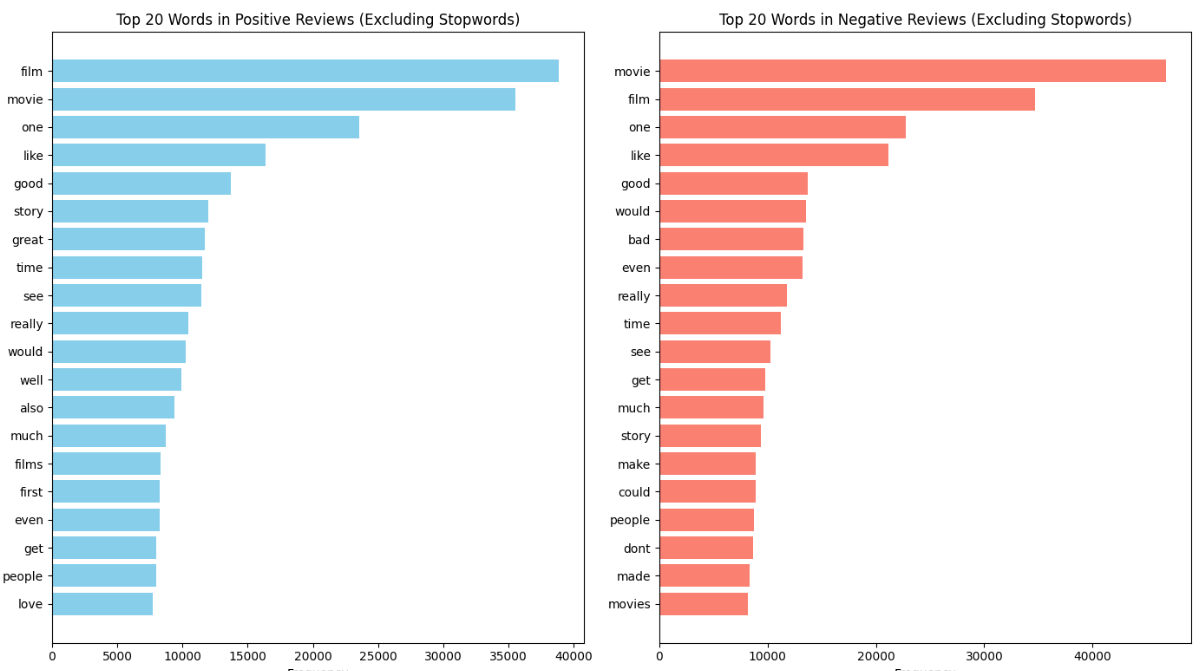
Next, we visualized the top 20 words in both positive and negative reviews, excluding unwanted words such as English stopwords (the, and, a, etc…) and HTML tags that made their way into the corpus. From these barplots, we can tell that there are definitely common terms between the two, such as “movie”, “film”, and “story”, as well as unexpected commonalities such as “like” and “good”. However, there are some distinct terms such as “great” and “bad” that are much more prevalent in one class than the other, making them ideal predictors for our models to train on.
Classifiers
Neural Networks were implemented using the TensorFlow library with the Keras API, while the remaining methods were implemented using scikit-learn.
The k-Nearest Neighbors classifier predicts a value by comparing it to the closest neighbors around it and going with the majority. For this reason it is common practice to use an odd number of neighbors to ensure there are no ties. We found that generally more neighbors means higher accuracy. The number of neighbors we tried as parameters were 1 ,5, 9, 15, and 29.
Logistic Regression is a commonly used statistical model where the goal is to predict one of two possible outcomes. The model utilizes a logistic function to map predicted values to their probabilities. Parameters we can tweak to tune the model include penalty (regularization), C (controls penalty strength), solver (which may introduce changes in performance or convergence), and max iterations.
Feedforward Neural Networks are a class of artificial neural networks where connections between the nodes do not form cycles. Each layer in an FNN is connected to the next one in a forward manner, starting from the input layer and proceeding through one or more hidden layers to the output layer. The network consists of an input layer, two to three hidden layers, and an output layer. The hidden layers use the ReLU activation function, and dropout layers are included to prevent overfitting.
Random Forests construct multiple Decision Trees during training and output the mode class of the individual trees. As it employs random feature selection, it can create diverse trees which should improve accuracy compared to if we were to fit a single tree. This makes it more robust to overfitting. Some parameters include number of estimators (trees), criterion (measures quality of split), max depth (of trees), and max features (number of features considered when looking for best split).
Experimental Setup
The IMDb dataset is already split up into test and train sets so there was no need to further separate them out. From here the reviews are split into 12.5k negative reviews and 12.5 positive reviews in both the test and train datasets for a total of 50k reviews. The metrics we considered were not just accuracy but also precision and recall since the project calls for binary classification. After setting up the classifiers, the only thing left to do was tune the hyperparameters to optimize for the best results possible. For kNN this meant tuning the number of neighbors and for the Feedforward Neural Network it was the number of hidden layers and units. In both instances increasing these numbers leads to more accuracy, although there is always a risk of overfitting. The Logistic Regression model was tuned using the C, penalty, solver, and max iteration parameters. Lastly, the Random Forest was tuned using the number of estimators, max depth, min samples split, min samples leaf, and max features.
Experimental Results
k-Nearest Neighbors: The k-Nearest Neighbors classifier did not perform as well as some of the others but it was able to hold its home. Overall, I saw the accuracy of the classifier increase along with the number of neighbors. I tried 1,5,9,15, and 29 neighbors. Between each one the score increased by an average of 0.02. The more neighbors I had the more diminishing returns I would see in accuracy, having to nearly double the amount of neighbors every time for a small increase in accuracy. The worst the model performed was with 1 neighbor at 63% accuracy and the best was with 29 neighbors at 72%. On the right are the results for K = 1, 15, and 29 respectively.
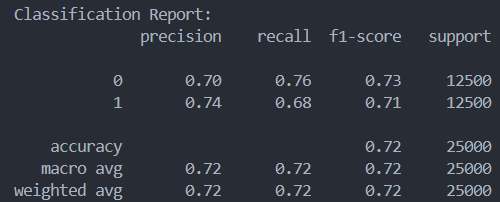
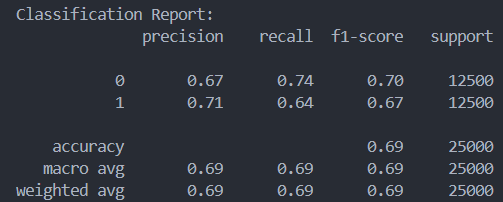
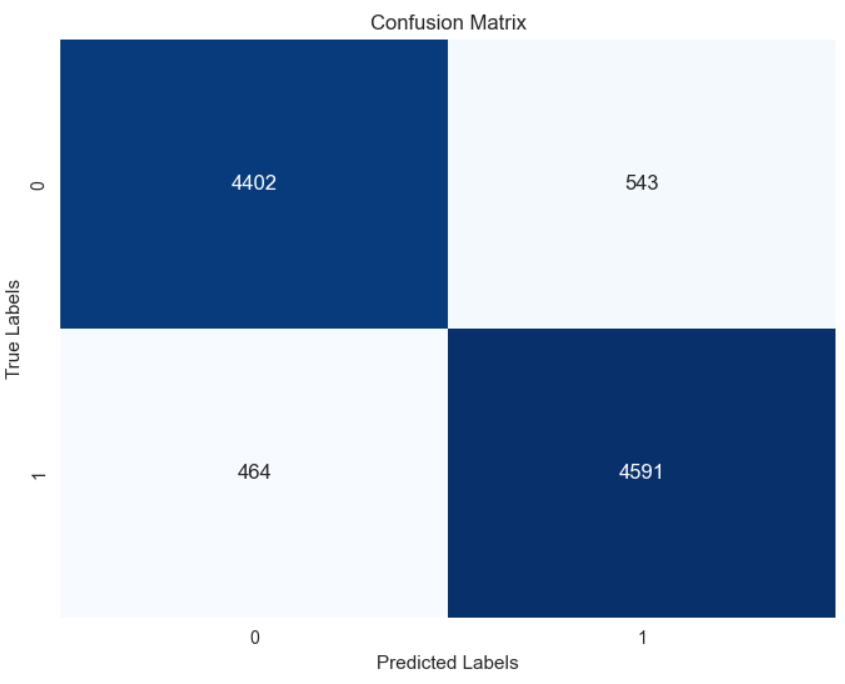
Logistic Regression: Fitting the dataset to a Logistic Regression model yielded much better results than kNN, achieving an accuracy of 89.9%. Precision and Recall scored pretty similarly at 89 and 90%, likely due to the cleanly split, balanced nature of the dataset. Setting the solver to ‘lbfgs’, the max iterations to 100, and penalty to ‘l2’ yielded the best accuracy on the testing set, bumping up the accuracy by about 2% from the original accuracy score. (Confusion Matrices in Appendix B)
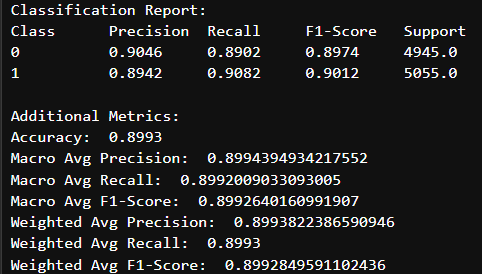
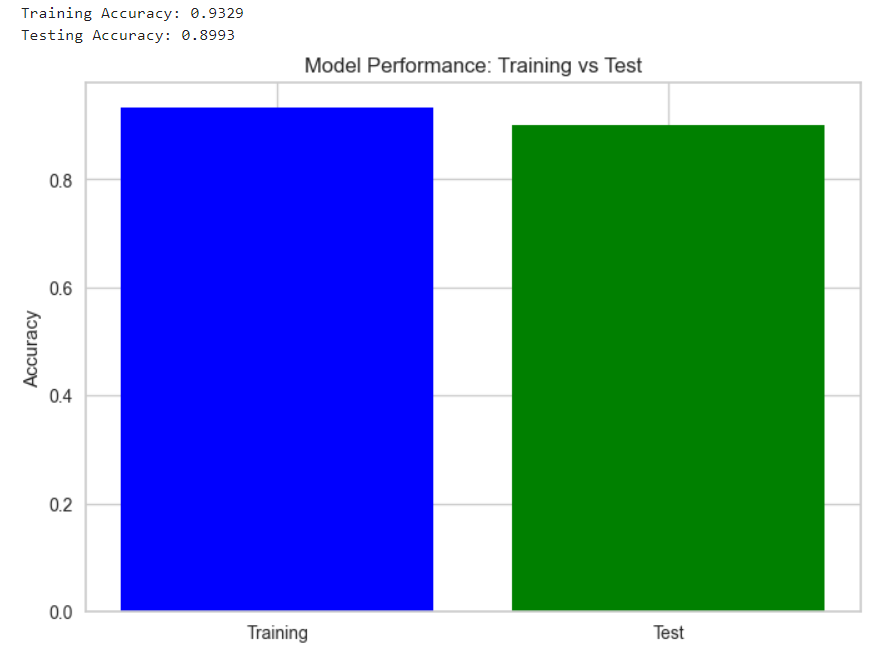
Additionally, when comparing the model’s performance on the training vs the testing dataset, we see a difference of only about 3%, which implies that although performance does decrease on unseen data, the model still generalizes reasonably well, which highlights Logistic Regression’s suitability to this dataset.
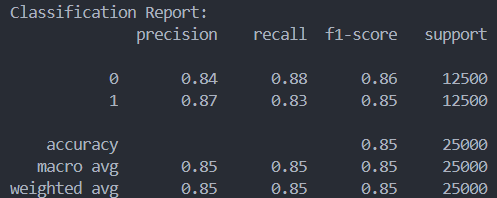
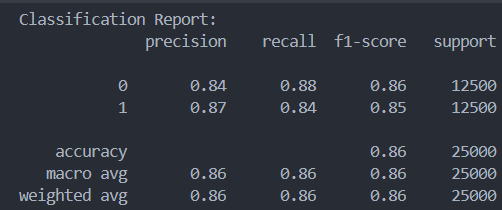
Feedforward Neural Networks: Overall the Neural Network performed very well at classifying the reviews at 85% accuracy. Recall was slightly better when three hidden layers were used but accuracy remained effectively the same. The combination of hidden layers/units used were (512, 256), (512, 256, 128), (512, 256, 128, 64). There wasn’t too much of a difference in the accuracy of the classifier based on tuning these hyperparameters. They all performed about the same.
(512,256) (512, 256, 128, 64)
Random Forest: Originally, we planned to use a Decision Tree to fit this dataset. However, with a relatively poor accuracy of 73%, we decided to use an ensemble method instead to account for the overfitting or high variance which could be hindering scores.
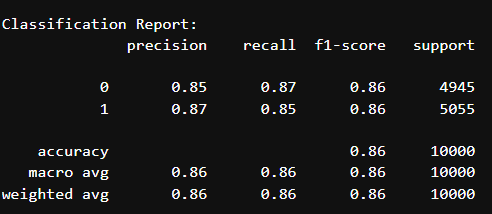
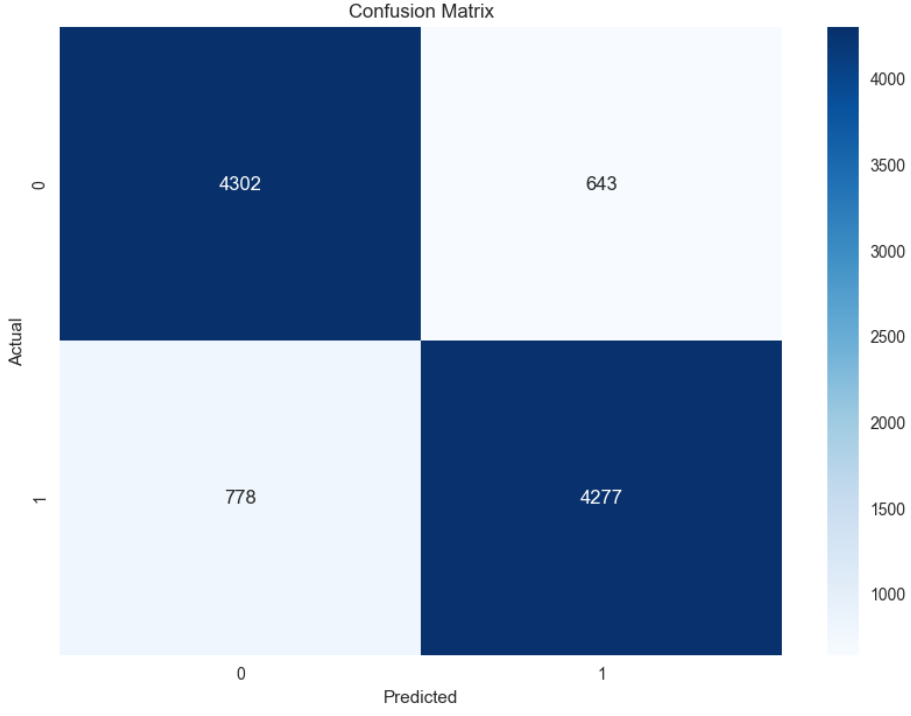
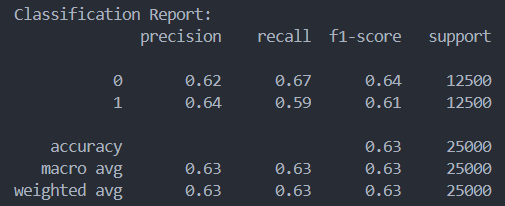
Sure enough, after fitting the dataset to a Random Forest instead, the model yielded much better results, beginning at an accuracy of around 83%. Furthermore, by increasing the number of trees to 200, setting the max_features to ‘sqrt’, and adjusting the minimum number of samples required to be a leaf to 5, accuracy increased to 86%. As shown in the below classification report, performance is quite balanced, indicating there is no bias towards one class.
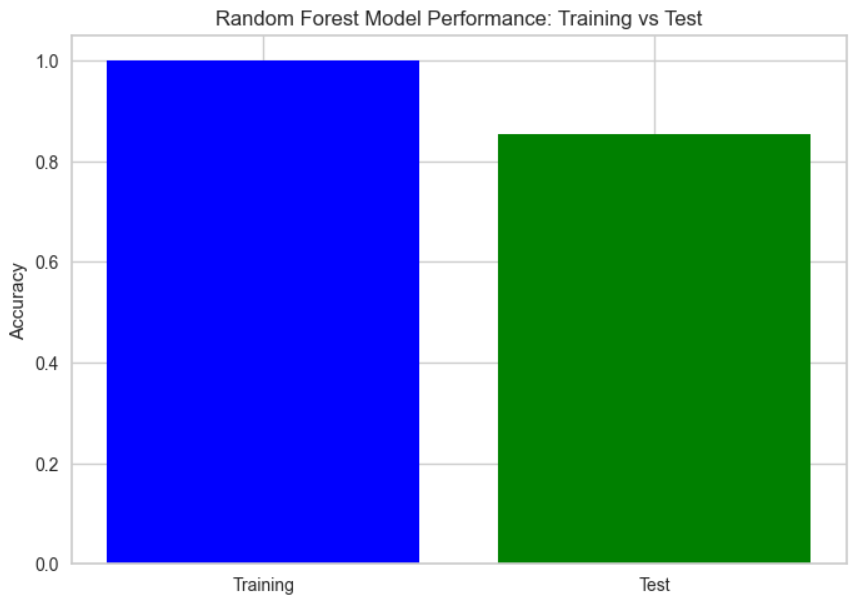
In terms of generalizability, the model seems to perform significantly better on the training data than the testing data, indicating that although it was the second most accurate model tested over the course of this project, it may be overfitting to the training data and needs further tweaking to be able to fit to unseen data.
Insights
kNN and Neural Networks:
What surprised me the most was how little my hyperparameter tuning did for the Feed Forward Neural Network. Changing the number of neighbors for the kNN classifiers drastically affected its accuracy so I was expecting the same to be true for the neural network. I’m sure I could have changed the values even more drastically than I did to see the results I wanted but I felt I had already changed them pretty significantly. I was also surprised to see kNN still gaining accuracy after so many neighbors already although I fear this may be a bit of overfitting.
Logistic Regression and Random Forest:
Some aspects of this project, such as the Random Forest model’s significant improvement on the single Decision Tree, were to be expected. However, the margin by which our Logistic Regression model outperformed the others was the most surprising discovery. It’s possible this implies there is an inherent linearity when it comes to the separation between sentiments in the given reviews. This may also be augmented by the fact that the dataset was evenly split, with neutral reviews being omitted from the training data, meaning there is a clear division even before we fit any models.
In terms of interpretability and generalizability, there were definitely instances of overfitting, with the worst example coming from the Random Forest model (although the discrepancy between the performances on the two sets was still somewhat reasonable). This also rounds back to explain a factor of why Logistic Regression may have performed so well; its simplicity was conducive to a smaller chance of overfitting, unlike the more complex models that were used alongside it.
Appendix A
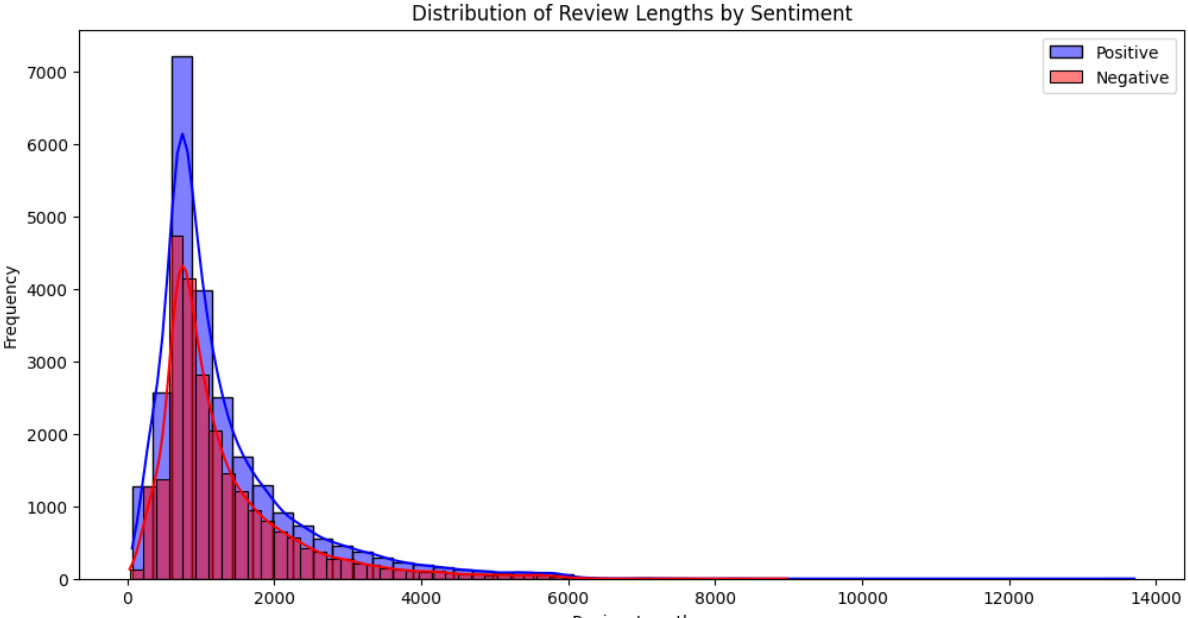
There seems to be a larger abundance of positive reviews compared to negative, although both distributions follow roughly the same right skewed shape, with a mode of review length around 1000 words.
Appendix B
Logistic Regression:
Random Forest: